In the fast-evolving digital marketing landscape of 2025, scraping Google Ad Results data has become a critical strategy for businesses aiming to gain a competitive edge. With Google commanding an 82% share of the global search market, its ad data—rich with insights on competitor strategies, keyword performance, and market trends - offers unparalleled value.
However, challenges like Google’s advanced anti-bot measures and the January 2025 JavaScript requirement have made data extraction more complex. This article explores these trends, outlines practical methods for developers to scrape Google Ad Results, and highlights how GoProxy’s residential proxies provide a robust solution to ensure anonymity, scalability, and success.
The Value of Google Ad Results Data
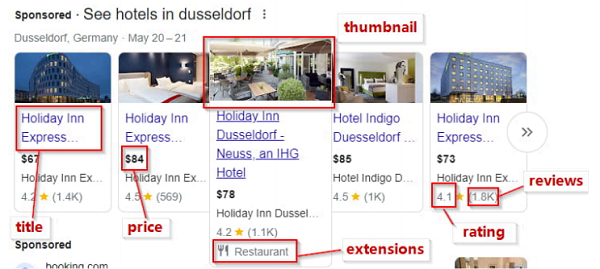
Google Ad Results contain structured data such as block_position (top, bottom, middle, or right), title, link, sitelinks, source, and more, all embedded within the ads array of a search result’s JSON output.
Extracting this data enables businesses to:
● Conduct competitive analysis by dissecting ad copy and targeting strategies.
● Enhance keyword research by identifying high-value terms driving ad placements.
● Monitor regional ad trends for localized campaign optimization.
Yet, scraping this data is no simple task. Google’s bot detection systems and dynamic content rendering demand sophisticated tools and techniques, making proxies an essential component of any scraping operation.
Trends Shaping Google Ad Scraping in 2025
AI-Powered Automation
The rise of AI-driven platforms like Gumloop, which secured $17M in Series A funding in January 2025, signals a shift toward automated ad scraping and content repurposing. These tools streamline workflows, enabling marketers to scrape competitor ad libraries in seconds. However, AI relies on robust data extraction, amplifying the need for proxies to handle large-scale requests without detection.
Google’s JavaScript Requirement
Since January 2025, Google mandates JavaScript execution for search results, as reported by TechCrunch. This shift means ad data is dynamically loaded, requiring headless browsers like Puppeteer, Selenium, or Playwright. While these tools handle rendering, they increase resource demands and expose scraping operations to detection without proper IP management.
The Indispensable Role of Proxies
Proxies remain vital for bypassing Google’s anti-bot systems. Residential proxies, in particular, mimic real user behavior by using IPs tied to actual devices, reducing the risk of IP bans and ensuring high success rates. This is especially critical for scraping voluminous or geolocation-specific ad data.
Practical Methods to Scrape Google Ad Results with GoProxy
For developers targeting Google Ad Results, a combination of headless browsers and GoProxy’s residential proxies offers a scalable, anonymous, and efficient approach. Below are three actionable methods, each addressing specific user needs and technical challenges.

Method 1: Basic Scraping with Headless Browsers and Proxies
Goal: Extract ad data for a single keyword query.
Steps:
1. Set Up a Headless Browser: Use Puppeteer to render JavaScript-heavy pages. Install it via npm install puppeteer.
javascript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.google.com/search?q=top+sights+paris');
await browser.close();
})();
2. Integrate GoProxy: Configure the browser to route requests through a residential proxy. Replace proxy Url with your GoProxy endpoint (e.g., http://username:[email protected]:port).
javascript
const browser = await puppeteer.launch({
args: ['--proxy-server=' + proxyUrl],
});
3. Extract Ads: Target the ads array data by parsing the rendered DOM.
javascript
const ads = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.ad-class')).map(ad => ({
title: ad.querySelector('.title')?.innerText,
link: ad.querySelector('a')?.href,
}));
});
Use Case: Ideal for small-scale testing or one-off analyses.
Method 2: Scaling with IP Rotation
Goal: Scrape ad data across multiple keywords or regions.
Steps:
1. Leverage GoProxy’s Rotating Proxies: Enable automatic IP rotation to distribute requests across GoProxy’s vast IP pool. Access this feature via their dashboard at Buy Residential Proxies - Get 7-Day Free Trial.
2. Batch Requests: Loop through a keyword list, rotating IPs per request.
javascript
const keywords = ['top sights paris', 'hotels dusseldorf'];
for (const keyword of keywords) {
const page = await browser.newPage();
await page.goto(`https://www.google.com/search?q=${encodeURIComponent(keyword)}`);
// Extract ads
await page.close();
}
3. Handle Rate Limits: Add delays (e.g., 2-5 seconds) between requests to mimic human behavior.
Use Case: Suited for medium-scale scraping with geolocation diversity.
Method 3: Advanced Parsing with Structured Output
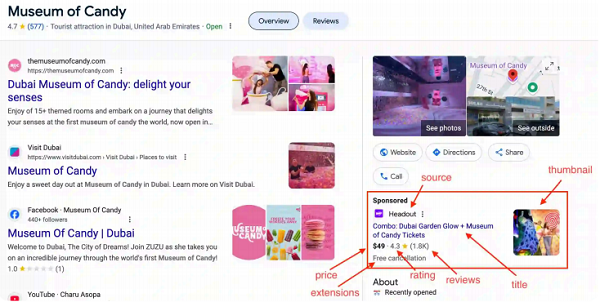
Goal: Extract detailed ad fields like sitelinks and block_position.
Steps:
1. Simulate Real Users: Combine GoProxy proxies with randomized user agents and viewport sizes in Puppeteer.
javascript
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36');
await page.setViewport({ width: 1280, height: 720 });
2. Parse Complex Data: Use DOM selectors or regex to extract fields like sitelinks or source.
javascript
const adDetails = await page.evaluate(() => {
const ads = [];
document.querySelectorAll('.ad-class').forEach(ad => {
const sitelinks = Array.from(ad.querySelectorAll('.sitelink')).map(link => link.innerText);
ads.push({
block_position: ad.dataset.position || 'unknown',
title: ad.querySelector('.title')?.innerText,
sitelinks,
});
});
return ads;
});
3. Store Data: Output results in JSON for analysis.
Use Case: Perfect for developers needing granular data for in-depth competitor analysis.
How to Overcome Scraping Challenges with GoProxy
Key Challenge 1: JavaScript Rendering
Google’s JavaScript requirement means static HTTP requests no longer suffice. Headless browsers solve this by rendering dynamic content, but they’re resource-intensive and detectable without IP diversity. GoProxy’s residential proxies complement this setup by providing millions of IPs across 200+ countries, ensuring each request appears unique and reducing server load.
Key Challenge 2: Bot Detection and IP Bans
Google tracks request patterns, flagging repetitive IPs or rapid queries. GoProxy counters this with:
● Automatic IP Rotation: Switches IPs seamlessly, mimicking organic traffic.
● Residential IPs: Tied to real devices, these IPs have higher trust scores than datacenter proxies.
● Global Coverage: Enables region-specific scraping without raising red flags.
Key Challenge 3: Scalability and Speed
Large-scale scraping demands fast, reliable connections. GoProxy’s infrastructure offers high uptime and optimized response times, while OkeyProxy provides an alternative with a 65M+ proxy pool for redundancy. Together, they ensure uninterrupted data extraction.
Practical Example
A developer scraping ad data for “hotels in Dusseldorf” might encounter ads with block_position: top, price, and rating. Using Method 3 with GoProxy, they could extract:
json
{
"position": 1,
"block_position": "top",
"title": "Holiday Inn Express Düsseldorf Airport",
"price": "$85",
"sitelinks": ["Free cancellation", "Pet-friendly"]
}
This data, scaled across hundreds of queries, empowers precise campaign adjustments.
Why GoProxy Stands Out
GoProxy’s residential proxies excel in:
● Anonymity: IPs from real users thwart detection.
● Scalability: Millions of proxies handle bulk requests effortlessly.
● Flexibility: Global IPs support localized scraping.
● Integration: Works seamlessly with headless browsers and custom scripts.
For developers, pairing GoProxy with tools like Puppeteer proxy pool creates a powerhouse for Google Ad Results scraping, balancing technical precision with operational ease.
FAQs: Scraping Google Ad Results with Proxies
1. How do I efficiently extract and categorize ads by block_position when scraping in bulk?
When scraping Google ad results, the block_position field (e.g., top, bottom, middle, right) indicates where ads appear on the page, which is critical for understanding ad visibility and performance.
To handle this in bulk: Parse the JSON response and group ads by block_position using a dictionary or similar structure.
● Challenge: High request volumes can lead to IP bans, disrupting data collection.
● GoProxy Advantage: GoProxy’s dynamic residential proxies rotate IPs seamlessly, ensuring uninterrupted scraping across thousands of queries. This allows you to categorize block_position data reliably, even for large-scale advertising analysis.
2. What’s the best way to handle missing or inconsistent fields like phone or sitelinks in the JSON output?
Google ad results in the ads array may not always include optional fields like phone or sitelinks, causing parsing errors or incomplete datasets during bulk scraping.
To manage this: Use conditional checks or default values when accessing these fields.
● Challenge: Network interruptions or blocks can corrupt JSON responses, exacerbating missing data issues.
● GoProxy Advantage: GoProxy’s stable residential proxies minimize connection drops, ensuring consistent JSON outputs. This reliability is key for advertisers tracking optional fields like phone for campaign insights.
3. How can I scrape and analyze source data to identify ad network origins in bulk?
The source field in the ads array identifies the ad network or provider (e.g., Google Ads, third-party networks), which is valuable for competitive analysis.
To process this in bulk: Extract the source field and aggregate it across multiple searches.
● Challenge: Frequent IP bans can halt data collection mid-process, skewing source distribution.
● GoProxy Advantage: GoProxy’s dynamic residential proxies provide high-volume IP rotation, enabling uninterrupted scraping of source data across global markets. This is ideal for advertisers mapping ad network prevalence.
4. How do I scale scraping to collect sitelinks data for thousands of keywords without triggering CAPTCHAs?
Sitelinks are nested within the ads array and provide additional links in ads, making them essential for SEO and campaign analysis.
To scale this:
● Use a proxy pool and rate-limit requests to mimic human behavior.
● Parse sitelinks with a nested loop:
python
import json
response = json.loads(api_response)
for ad in response.get("ads", []):
for sitelink in ad.get("sitelinks", []):
print(f"Sitelink: {sitelink['title']} -> {sitelink['link']}")
● Challenge: Google’s CAPTCHA triggers can block bulk requests, especially for dynamic fields like sitelinks.
● GoProxy Advantage: GoProxy’s dynamic residential proxies use real user IPs, reducing CAPTCHA triggers. With 200+ country coverage, you can scrape sitelinks for keyword-specific ads worldwide, enhancing advertising strategy insights.
5. How can I ensure data accuracy when scraping title and link fields across multiple regions?
The title and link fields are core ad components, but their accuracy depends on consistent geolocation and stable connections. To ensure precision:
● Use region-specific proxies and validate responses against expected formats.
● Example:
python
import json
response = json.loads(api_response)
for ad in response.get("ads", []):
title = ad.get("title", "")
link = ad.get("link", "")
if title and link: # Validate non-empty
print(f"Title: {title}, Link: {link}")
● Challenge: Proxy failures or regional blocks can return mismatched or incomplete title/link data.
● GoProxy Advantage: GoProxy’s dynamic residential proxies offer precise geolocation targeting and reliable uptime, ensuring accurate title and link extraction for region-specific ad campaigns. This is crucial for advertisers optimizing multi-market strategies.
Final Thoughts
Scraping Google Ad Results data in 2025 requires navigating AI automation trends, JavaScript rendering, and stringent bot defenses. GoProxy’s residential proxies address these challenges head-on, offering developers a reliable, anonymous, and scalable solution.
By following the methods outlined—basic scraping, IP rotation, or advanced parsing—technical teams can extract actionable ad insights with confidence.
Explore Buy Residential Proxies - Get 7-Day Free Trial to streamline your scraping operations and unlock the full potential of Google Ad Results data.











