Web scraping uses code to extract data from websites automatically. It gathers information with high efficiency and flexibility for data analysis, market research, price monitoring, etc. While Python dominates the web scraping landscape, R is another popular choice, especially for data scientists preferring working within the R ecosystem.
In this beginners' guideline, we will explain how to do web scraping in r in detail, covering:
- Basic web scraping in R using rvest (for static websites).
- Dynamic web scraping in R using RSelenium (to scrape JavaScript-heavy websites).
- Advanced web scraping in R
- Best practices & avoiding bans
Keep this as simple as possible so that you can understand and start.
What is Web Scraping in R?

Web scraping in R involves extracting data from websites using specialized libraries that automate HTTP requests and parse HTML content. This is useful for collecting product prices, news articles, financial data, and social media trends for analysis.
The most commonly used R packages for web scraping include:
- rvest – Best for scraping static websites with structured HTML data.
- RSelenium – Ideal for handling JavaScript-heavy websites requiring a headless browser.
- httr – Useful for making HTTP requests with custom headers and proxy support.
Each of these tools serves a different purpose, and choosing the right one depends on whether you’re dealing with static or dynamic content.
Why Use R for Web Scraping?
R offers several advantages for web scraping, especially among data scientists and analysts:
- Easy-to-use and powerful libraries: R has rich libraries such as rvest, httr, and RSelenium specifically suitable for web scraping.
- Seamless data integration: Scraped data can be directly analyzed in R.
- Data Visualization: R’s extensive visualization packages allow you to create insightful graphics from collected data seamlessly.
- Strong community support: With a vibrant user community, finding help and related resources is relatively easy.
Web Scraping vs. APIs: Legal and Ethical Considerations
Before scraping a website, check if it provides an API (Application Programming Interface). APIs are often the preferred way to access structured data legally. Use web scraping when APIs don’t exist or have limitations.
| Feature |
Web Scraping |
APIs |
| Ease of Use |
Requires parsing HTML |
Structured JSON/XML format |
| Data Availability |
Any visible webpage data |
Limited to API endpoints |
| Speed |
Slower (HTML parsing) |
Faster (direct data access) |
| Risk of Blocking |
High (anti-scraping measures) |
Low (if API access is granted) |
Understanding HTML & CSS for Web Scraping
Web pages are built using HTML (HyperText Markup Language). To extract data, we need to locate elements using:
- CSS Selectors (e.g., .class-name, #id-name, div > p).
- XPath Queries (e.g., //h1, //table[@class='data']).
Example: HTML Structure of a Product Page

To extract the title, we can use:
CSS Selector: .product .title
XPath: //div[@class='product']/h2
Setting Up Your Web Scraping Environment in R
To begin with web scraping in R, you'll need:
1. R installed on your computer
You can download it from CRAN.
2. RStudio
This is an integrated development environment (IDE) for R that makes coding easier. Download it here.
3. Relevant R packages
You will need to install a few libraries. Use the following commands in your R console:

For Copy:
install.packages("rvest")
install.packages("httr")
install.packages("RSelenium")
install.packages("xml2")
4. Now, let’s load them

For Copy:
library(rvest)
library(httr)
library(RSelenium)
library(xml2)
Basic Web Scraping in R (Static Websites) with rvest
For websites with static HTML content, we can use rvest.
Example: Scraping Product Prices
Step 1: Send an HTTP Request to Retrieve the Page

For Copy:
url <- "https://example.com/products"
page <- read_html(url)
Step 2: Extract Data Using CSS Selectors

For Copy:
titles <- page %>% html_nodes(".title") %>% html_text()
prices <- page %>% html_nodes(".price") %>% html_text()
Step 3: Store Data in a Data Frame

For Copy:
data <- data.frame(Product = titles, Price = prices, stringsAsFactors = FALSE)
print(data)
This method works well for static websites where data is directly available in the HTML.
Dynamic Web Scraping in R (JavaScript-Rendered Pages) with RSelenium
Some websites load content dynamically using JavaScript. rvest won’t work here. To handle this, we use RSelenium, which controls a real web browser to extract data.
Step 1: Start an RSelenium Session

For Copy:
rD <- rsDriver(browser = "chrome", chromever = "114.0.5735.90")
remDr <- rD$client
remDr$navigate("https://example.com/dynamic-content")
Step 2: Extract JavaScript-Rendered Elements

For Copy:
webElem <- remDr$findElement(using = "css selector", ".dynamic-data")
data <- webElem$getElementText()
print(data)
Use this method when dealing with JavaScript-heavy websites like Google Search, LinkedIn, or Twitter.
Advanced Web Scraping Techniques in R
As websites implement anti-scraping mechanisms and rely more on JavaScript for content loading, we need advanced techniques to extract data efficiently. Below are some powerful methods to enhance your web scraping workflow in R.
1. Web Crawling in R (Scraping Multiple Pages)
Web crawling involves extracting data from multiple pages by iterating through URLs.
Example: Scraping Multiple Pages of a Product Listing
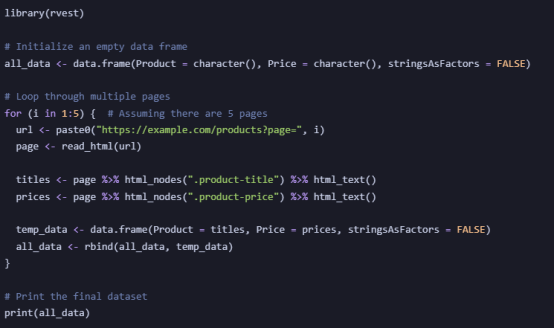
For Copy:
library(rvest)
# Initialize an empty data frame
all_data <- data.frame(Product = character(), Price = character(), stringsAsFactors = FALSE)
# Loop through multiple pages
for (i in 1:5) { # Assuming there are 5 pages
url <- paste0("https://example.com/products?page=", i)
page <- read_html(url)
titles <- page %>% html_nodes(".product-title") %>% html_text()
prices <- page %>% html_nodes(".product-price") %>% html_text()
temp_data <- data.frame(Product = titles, Price = prices, stringsAsFactors = FALSE)
all_data <- rbind(all_data, temp_data)
}
# Print the final dataset
print(all_data)
Automates scraping across multiple pages without manually changing URLs.
2. Parallel Web Scraping in R (Speed Optimization)
Scraping large datasets can be slow if done sequentially. We can speed up the process using parallel computing with the foreach and doParallel packages.
Example: Running Multiple Scraping Sessions in Parallel
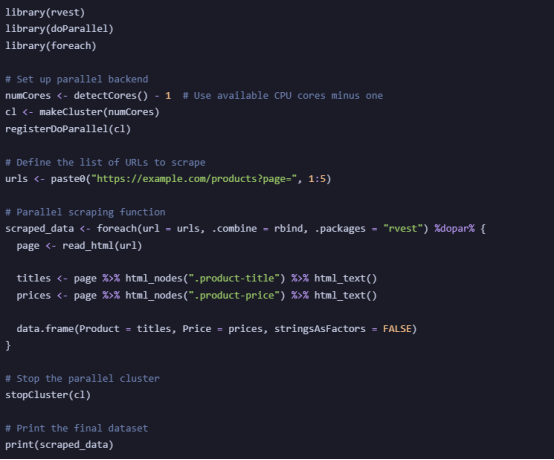
For Copy:
library(rvest)
library(doParallel)
library(foreach)
# Set up parallel backend
numCores <- detectCores() - 1 # Use available CPU cores minus one
cl <- makeCluster(numCores)
registerDoParallel(cl)
# Define the list of URLs to scrape
urls <- paste0("https://example.com/products?page=", 1:5)
# Parallel scraping function
scraped_data <- foreach(url = urls, .combine = rbind, .packages = "rvest") %dopar% {
page <- read_html(url)
titles <- page %>% html_nodes(".product-title") %>% html_text()
prices <- page %>% html_nodes(".product-price") %>% html_text()
data.frame(Product = titles, Price = prices, stringsAsFactors = FALSE)
}
# Stop the parallel cluster
stopCluster(cl)
# Print the final dataset
print(scraped_data)
Scrapes multiple pages simultaneously, reducing execution time significantly.
3. Using a Headless Browser for JavaScript-Rendered Content
Some websites load content dynamically using JavaScript. rvest alone cannot scrape such pages, so we use RSelenium to automate a headless browser (a browser that runs without a graphical interface).
Example: Scraping JavaScript-Rendered Content with RSelenium
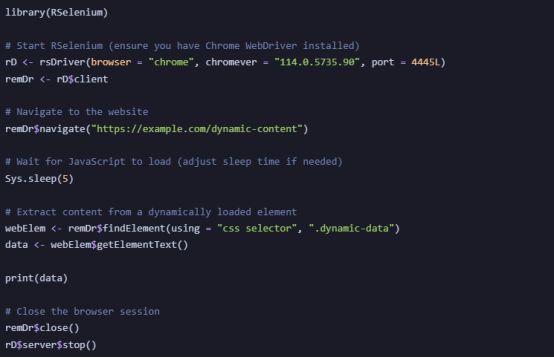
For Copy:
library(RSelenium)
# Start RSelenium (ensure you have Chrome WebDriver installed)
rD <- rsDriver(browser = "chrome", chromever = "114.0.5735.90", port = 4445L)
remDr <- rD$client
# Navigate to the website
remDr$navigate("https://example.com/dynamic-content")
# Wait for JavaScript to load (adjust sleep time if needed)
Sys.sleep(5)
# Extract content from a dynamically loaded element
webElem <- remDr$findElement(using = "css selector", ".dynamic-data")
data <- webElem$getElementText()
print(data)
# Close the browser session
remDr$close()
rD$server$stop()
Scrapes JavaScript-heavy websites that rvest cannot handle.
Avoiding IP Blocks & Anti-Scraping Measures
Many websites implement anti-scraping mechanisms, such as blocking repeated requests from the same IP address, detecting bot-like behavior (e.g., too many requests in a short time), and using CAPTCHAs to prevent automated access.
1. Use Headers & User-Agent Strings (Mimic a real browser request)

For Copy:
library(httr)
url <- "https://example.com"
page <- GET(url, user_agent("Mozilla/5.0 (Windows NT 10.0; Win64; x64)"))

For Copy:
proxy_url <- "http://your-proxy-server.com:8080"
page <- GET(url, use_proxy(proxy_url))
3. Introduce Random Delays Between Requests (Avoid making too many requests too quickly)

For Copy:
Sys.sleep(runif(1, 2, 5)) # Wait between 2 to 5 seconds randomly
4. Check robots.txt Before Scraping (Respect website policies)
FAQs About Web Scraping in R
1. Can I scrape any website with R?
No, always check the website’s robots.txt file.
2. How do I avoid getting blocked while scraping?
Use proxies, rotating User-Agents, and slow request intervals.
3. What are the best libraries for web scraping in R?
rvest for HTML scraping, httr for HTTP requests, and RSelenium for JavaScript-rendered pages.
4. What’s the best proxy type for web scraping in R?
Rotating residential proxies offer the highest success rate for large-scale scraping.
Final Thoughts
Web scraping in R is a powerful technique for extracting valuable data from websites. By leveraging tools like rvest and RSelenium, along with proxy integration, you can scrape efficiently while avoiding bans.
Need reliable scraping proxies? Get started today with our premium proxy solutions! Besides pay-as-you-go, we newly offer unlimited rotating residential proxy plans for high demand. Free trial for your worry-free experience, take your data collection skills to the next level!











